On Graphcore
Updated 2026-02-23 / Created 2026-02-23 / 2.52k words
Trying exotic parallel processing hardware which is dead for fairly good reasons.The farther you get away from the flops in the physical register file; the longer the wires get, the less bandwidth there is; and with those the microarchitecture's magic fades, its power and abstractions decay, and you are left with the mundane, real, and slow.
I've briefly talked about Graphcore, a (perhaps the) British AI startup, which designed AI accelerators ("Intelligence Processing Units") with a novel architecture, in my post comparing accelerators, as an example of all-SRAM designs like Groq and Cerebras, but I recently looked again as part of an ongoing program of hardware upgrades. Their commercial failure[1] – they are in some sense alive, and are hiring people, but were sold to SoftBank for a pittance after running out of money, lost their CTO in 2025 and have not released any new products since 2022[2] – was in spite of clever engineering and surprisingly prescient design.
Graphcore IPU chips contain ~1000 independent cores ("tiles"), whereas modern CPUs and GPUs have ~100 and ~500 respectively (the "CUDA cores" in an Nvidia GPU are not true independent cores, and by this standard recent CPUs have about 32 "cores" per core[3]). They hide latency with simple barrel threading – six threads run round-robin. GPUs, instead, have systems to schedule lots of threads onto execution when they're ready to run, and CPUs split up and rearrange instruction streams to achieve the highest single-threaded performance. IPUs can avoid these due to their simpler memory hierarchy: they don't have (hardware-managed) caches or local DRAM, the timings of which can't easily be modelled at compile time. Their only onboard memory is ~600kB of SRAM per core[4], which is accessible quickly and with constant latency, hence why they quote bandwidth figures like 60TB/s. This is only achievable if your code is entirely memory accesses, so I think it's more useful to think of it as providing zero-wait local memory access. Inter-core communication requires an all-core sync barrier (~100ns) and cycle-precise scheduling by the compiler, since the on-chip network ("Exchange") doesn't buffer. Inter-chip communication can run over PCIe to the host (where there is one) or dedicated "IPU-Links" (~hundreds of GB/s); within-chip syncs can be done without an all-chip sync because of the lower bandwidth between IPUs than within IPUs. Inter-IPU sync latency[5] is apparently in the tens of nanoseconds – below normal DRAM access times and faster than some L3 caches!
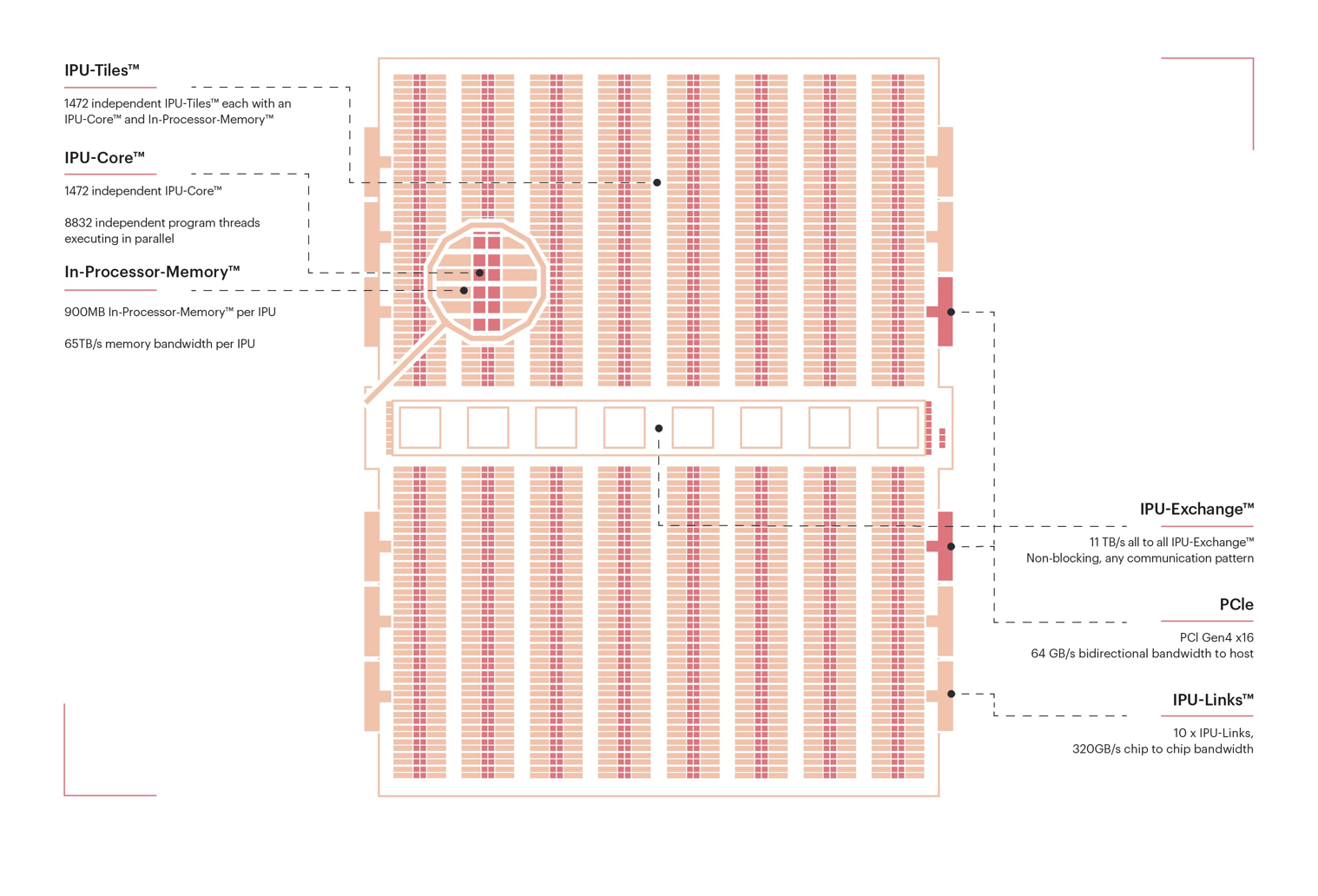
IPU architecture diagram via Graphcore docs.
Why this architecture? Graphcore has made different claims about it over the years, being quite an old company by AI standards (their founding in 2016 predates transformers and I imagine they had the core ideas beforehand). The most obvious reason for their design is sparsity support and overfitting to contemporary RNNs/CNNs[6], but there are better reasons. GPT-5.2-high found a presentation from 2018 justifying their strategy. They correctly determined that power would be a binding constraint on future AI hardware, that direct-to-GPU interconnects would need to scale beyond a single node and that memory bandwidth would continue to be a bottleneck. Also, they added hardware-accelerated stochastic rounding for low-precision training in their first generation, while Nvidia only integrated this in recent Blackwell GPUs[7]. Later, they talk about the power and cost advantages of avoiding HBM, and how having enough SRAM allows using DRAM with lower bandwidth.
Most of these arguments and decisions are essentially correct, and very early: the overall Graphcore design was locked in a decade ago, but it's only in the past two or three years that datacentre buildouts became heavily power-constrained, Nvidia started scaling NVLink to racks, and HBM became supply-crunched (due to advanced packaging in ~2023 and memory production in ~2025[8]) rather than merely costly. Some have blamed their lack of adoption on the architecture being difficult to program but this fails to distinguish them from competitors: efficient GPU kernels involve all kinds of arcana even without newer sometimes-programming-model-breaking innovations such as tensor cores, TMA asynchronous loads, Blackwell's async matrix multiplications, new low-precision floating point formats, partitioning SMs into compute and communication, Hopper's cursed swizzles, and nonsense compiler quirks. Google TPUs used to require you to write TensorFlow code and have no public way to write low-level code for cases where the compiler isn't sufficient, and many were willing to put up with this agony because they were reasonably fast and free for some hobbyists[9], and they have a number of external customers these days. Graphcore IPUs lack a performant "eager mode" experience like GPUs, which puts off researchers, but this is also true of TPUs, as are the long compile times[10]. TPUs and GPUs are (were) more accessible to hobbyists and consumers, but this feels an unreasonably self-serving explanation, IPUs were given to many researchers, and large B2B sales (which they had, or at least tried for) should have been less affected by this.
You could argue that they missed out on the bitter lesson. This appears partly true – an early talk has their CTO expect that tensor compute would be less important in the future, that future workloads would be more heterogeneous, and that different specialized architectures would need to be designed/searched for different tasks – but regardless of their opinions, the chips are flexible enough that they can run transformers. The lack of directly-attached DRAM is problematic with big models (which I don't think they anticipated), but, as they describe, the capacious on-chip SRAM makes it tractable in principle to stream weights from cheap high-capacity server DRAM rather than use HBM[11], as long as your workloads aren't especially latency-sensitive[12]. Aside from interactive chatbots and now reinforcement learning training, most inference involving models big enough for this to be a problem isn't very latency-sensitive. I think the immediate cause of Graphcore's commercial failure was the end of their deal with Microsoft in October 2022; unless someone involved was very perceptive[13] (and saw no value in having IPUs for training), it is unlikely that the deal was shelved over concerns about LLM inference. My sense is that it's something like "nobody ever got fired for buying Nvidia" – people are and were used to Nvidia GPUs despite their bad system-level design (high power draw per accelerator[14], enormous failure rates, limited integrated networking), they were easy to prototype things on, and because transformers fit GPUs (and TPUs) well, Graphcore could win on cost grounds at best. Also, according to dubiously sourced slides, they were planning to skip 5nm manufacturing and go straight to TSMC N3, which was delayed about a year and had yield problems (hence N3B and the relaxed N3E), so in 2022 they were competing against newer and very capable Nvidia H100s with a two-year-old chip. We must wonder whether any prototype Mk3 IPUs were ever built.
However, I have an insatiable yearning for more TFLOP/s and exotic computer equipment, as well as some spare PCIe slots, and it turns out that (despite Graphcore's apparent focus on large customers and datacentres), some hardware made it out to the secondary markets. As well as C2 IPU cards (including engineering samples) which occasionally appear on eBay, I found C600 IPUs selling on the secret Chinese internet[15]. Graphcore's naming scheme is confusing – they have three publicly disclosed chip generations, which are Mk1 (~300MB SRAM, 1216 cores), Mk2 (~900MB SRAM, 1472 cores) and Bow (Mk2 but with higher clocks through improved manufacturing, and FP8 support), C2 (2x Mk1 IPU) and C600 (1x Bow IPU) PCIe cards, and various larger-scale rack/"pod" systems[16].
They're probably not available in quantity, but at $500 (plus shipping) per C600, and about the nominal compute of an A100 or 4090, C600s offer the best TFLOP/s/$ of any available product I know of by a large margin, with the possible exception of old V100 GPUs, with the main downsides being the lack of memory and questionable software support. As someone who often runs compute-intensive but small embedding models, and is willing to tolerate vast quantities of software jank, this fit well, and I ordered one.

The C600 on a desk before I installed it. It's slightly grubby from, presumably, prior use. I wonder what it was used for. Strangely, it came in a quantity-1 box with Graphcore branding and a decent amount of empty space – did they not care much about packaging efficiency, or were they being sold in extremely small quantity?
It failed to turn on when I installed it, but it turns out I had just forgotten to connect one end of the power cable[17]. Somewhat surprisingly, my guesswork-based patch to the kernel module worked fine, and the 2020-vintage CLI tools worked as expected[18], except the FLOP/s benchmark gc-flops, which exited early for some reason and returned an infeasibly high result. I got IPUpy, which runs 1472 Python interpreters concurrently, to work with some minor tweaks, but IPUDOOM failed with a mysterious linker error after I spent 30 minutes waiting for GCC 7 to compile. This turned out to be because it shipped an opaque precompiled binary (for the wrong IPU architecture) with code for JITing cross-tile communications (normally this is meant to be statically compiled on the host)[19].
Actual ML workloads were harder. I wanted to run the SigLIP image encoder model previously used for my meme initiatives. In principle, with 0.7 model TFLOPS, 280TFLOP/s of FP16 and a reasonable 60% MFU, I should have been able to do 250 images per second. With 400 million parameters and 900MB of SRAM, I needed to use FP8, which the chip supports at double rate, so it should have been possible to go even faster. After spending several hours wrangling ONNX and PopRT, since FP8 support was seemingly never added to their PyTorch fork, I was able to execute the model, but only at an infeasibly low 100 images per second[20], because I could only run at batch size 1, because at any higher batch size I got to experience the compiler spinning for ten minutes then producing "insufficient tile memory" errors. The profiling tool, which still worked after unpacking it and running it with a newer Electron version, helpfully broke down cycle count by kernel, showing that enormous amounts of time were spent in some kind of on-tile copy operation and presumably-low-utilization matrix multiplies. With all the layers of abstraction between the model and hardware, I did not know why, however.
I suspected that it might have been due to inefficient attention computation. There is a Flash Attention for IPU, but it's very unready and only works with Torch, which, as we established, does not work with FP8 in the outdated SDK. Poking at the open-source code further revealed nothing to me but enormous amounts of unpleasant C++ slop. In my hubris, I thought that with modern LLM technology it should be possible to simply replace all the inconvenient parts – the ML compiler and planner logic, but not the compiler and LLVM backend for individual tiles, which seems fine, and the low-level driver – with a cut-down pipeline for transformer inference only. Graphcore was going for training support and multi-IPU operation, and cared about complex mostly-convolutional models (in fact, matrix multiplies are handled as 1x1 convolutions), which I can ignore. However, to generate useful code, you need to be able to operate across multiple tiles, and that requires exchange code generation[21], and for some reason this is both closed-source and much more complicated than the "compute some timings, set four registers and trigger sync" I had anticipated. Reverse-engineering efforts are ongoing.
Even without this, there are some possible applications which do work quite well. Small GPT-2 training was perfectly operable when I tested it, and the stack seems good enough for my other very-small-model work. If anyone knows where the "Pod" hardware went (there used to be cloud offerings, but no more), I would like to try some out too.
Unlike many other startups, they had a coherent idea and succeeded in shipping two generations of basically-functional hardware and software, which is commendable. They also still retain an ML research team which produces decent work. ↩︎
There were vague rumours of another generation of IPUs being designed (publicly, this presentation), but no public concrete information currently. ↩︎
SIMD lanes in AVX-512 units are close to "CUDA cores". The GPU "core" number I used is SMSPs. ↩︎
Less on the first Mk1 IPUs. ↩︎
Not data latency, which is 250ns. There are separate cables for sync. ↩︎
The underlying assumption here may have been that future AI would be human-brain-like (highly bandwidth-bound, small batch size, weight-sharing mostly temporally), but I have no way to tell. The company's enjoyment of their circular, loosely brain-looking, unhelpful-for-parsing-architectures neural net diagrams slightly supports this. ↩︎
Tenstorrent had it earlier than Nvidia, but it has been bugged for generations: the functional model is slightly defective. ↩︎
It is possible that we'll see shortages in advanced logic soon. I don't know enough about the market to say why we don't seem to have. ↩︎
There's some history here with TPU Podcast and later EleutherAI and GPT-Neo which is as far as I know almost totally undocumented. ↩︎
Possibly it's that Google's software is/was less annoying, or they were more willing to "eat bitterness" and make their engineers and researchers do more work to save money at scale, especially because TPUs avoided more external margins. ↩︎
This is also possible with GPUs (with their VRAM and main system memory). This is loosely related to how FSDP works. ↩︎
If your model does fit in SRAM then inference could be extremely fast: as I mentioned before, this is how Cerebras and Groq operate. However, you need lots of chips, and software which works. ↩︎
This is possible! Recall that GPT-4 was trained around August 2022, months before ChatGPT (the release was later, due to extended internal testing). ↩︎
Graphcore explicitly calls this out and says that power simply couldn't go higher than contemporary V100 GPUs (300W). Ultimately, it could, with Nvidia's new B200s pushing 1000W (though this has been challenging and expensive, and they can't be deployed everywhere). The HBM situation is similar, with incremental changes pushing up capacity and bandwidth (admittedly at great cost). ↩︎
Xianyu, via Superbuy. ↩︎
They wanted to focus on complete systems after their first generation, but apparently the Chinese market wanted more flexible PCIe cards, so they had to release C600. There might have been an export-controls reason, but I don't know of any which affected the pods and not the PCIe cards. ↩︎
EPS, not 8-pin PCIe like on consumer GPUs. Adapters are readily available. ↩︎
Unlike much of the rest of the stack, these do not have available source code. ↩︎
As the "IPU21" architecture in the chip is very close to the "IPU2" of the binary, it can be patched to operate anyway. It appeared to run properly after that, though I don't know how to play Doom. ↩︎
On lower power than my RTX 3090, admittedly, which is something. ↩︎
In principle the existing library could do this, but I don't want to interact with lots of C++ code and it seems quite opinionated. ↩︎