Sparse autoencoders for meme retrieval
Updated 2024-10-06 / Created 2024-10-06 / 1.08k words
As ever, AI safety becomes AI capabilities.The fact that you can build a chatbot out of a statistical abstract of all human language is among the least interesting things about a statistical abstract of all human language.
Meme search has become an increasingly contested field as more and more people have begun noticing it as a trivial application of CLIP, and Meme Search Engine has several more competitors now, including one retroactively created in 2021 and most recently (that I know of) one made by some random Twitter user. Our memeticists have been hard at work developing new technologies to remain unquestionably ahead, and the biggest change in the pipeline is switching from semimanual curation (scrapers harvest and filter new memes and I make the final quality judgment) to fully automated large-scale meme extraction. Scaling up the dataset by about four orders of magnitude will of course make finding desirable search results harder, so I've been prototyping new retrieval mechanisms.
The ideal solution would be a user-aware ranking model, like the existing MemeThresher system but tailored to each user, but Meme Search Engine has no concept of users and I don't have the data to make this work easily (making each user manually label pairs as I did is not a great experience). Instead, my current work has attempted to make it fast and easy to refine queries iteratively without requiring users to precisely phrase what they want in text. Ideally, this could be done rapidly by eye tracker or some similar interface, but for now you press buttons on a keyboard like with everything else.
Queries are represented as CLIP embedding vectors (internally, the server embeds image/text inputs and then sums them), so the most obvious way to do this is to provide an interface to edit those. Unfortunately, manually tweaking 1152-dimensional vectors tightly optimized for information content and not legibility is hard. Back in the halcyon days of GANs, Artbreeder attempted to solve a problem like this in image generation; I attempted the most cut-down, rapidly-usable plausible solution relating to this which I could think of, which was to pick a random vector at each step and show the user the results if they moved their current query forward or backward on that vector.
This, however, also doesn't work. Randomly moving in embedding space changes many things at once, which makes navigation tricky, especially since you can only see where you are from a short list of the best-matching search results. I did PCA at one point, but the highest-variance components are often still strange and hard to understand. The naive solution to this is to alter single components of the query vector at once, but early work in mechanistic interpretability[1] has demonstrated that the internal representations of models don't map individual "concepts" onto individual basis directions – this makes intuitive sense, since there simply aren't that many dimensions. There is a solution, however: the sparse autoencoder.
Sparse Autoencoders
Normal autoencoders turn a high-dimensional input into a low-dimensional compressed output by exploiting regularities in their datasets. This is undesirable for us: the smaller vectors are more dense, inscrutable and polysemantic. Sparse autoencoders are the opposite: they represent inputs using many more features, but with fewer activated at the same time, which often produces human-comprehensible features in an unsupervised fashion. They draw from lines of research significantly predating modern deep learning, and I don't know why exactly they were invented in the first place, but they were used more recently[2] for interpreting the activations of toy neural networks, and then found to scale[3] neatly to real language models.
A few months ago[4], it was demonstrated that they also worked on image embeddings, though this work was using somewhat different models and datasets from mine. It also tested using SAEs to intervene in image generation models which take CLIP embeddings as input, which I have not tried. I have about a million embeddings of images scraped from Reddit as part of my ongoing scaling project, and chose these for my SAE dataset.
I wrote a custom SAE implementation based on OpenAI's paper[5] – notably, using their top-k activation rather than an explicit sparsity penalty, and with their transpose-based initialization to reduce dead features. Surprisingly, it worked nicely with essentially no tuning (aside from one strange issue with training for multiple epochs[6]) – the models happily and stably train in a few minutes with settings I picked arbitrarily. Despite previous work experiencing many dead features (features which are never nonzero/activated), this proved a non-issue for me, affecting at worst a few percent of the total, particularly after multiple epochs. I don't know why.
The downstream result I'm interested in is, roughly, sensible monosemantic features, so I have a script (adapted from the one for PCA directions) which pulls exemplars from the Meme Search Engine dataset (different from the SAE training dataset, since I didn't retain the actual images from that for storage space reasons) for each one. The 5-epoch model's features can be seen here and the 1-epoch checkpoint's here – there are 65536 total features, so I split them into chunks of 512 to avoid having to ship hundred-megabyte HTML files.
Results
It worked strangely well: the very first feature I saw (the script sorts features within a chunk by activation rate on the validation set) was clearly interpretable (it was blue things) and even cross-modal – one top result contains little of the color blue, but does contain the text "blue". Many are less clear than this (though there are things which are fairly clearly "snow", "boxes", "white things on white backgrounds" and "TV debates", for example), but even the ones with an unclear qualitative interpretation are thematically consistent, unlike with random vectors.
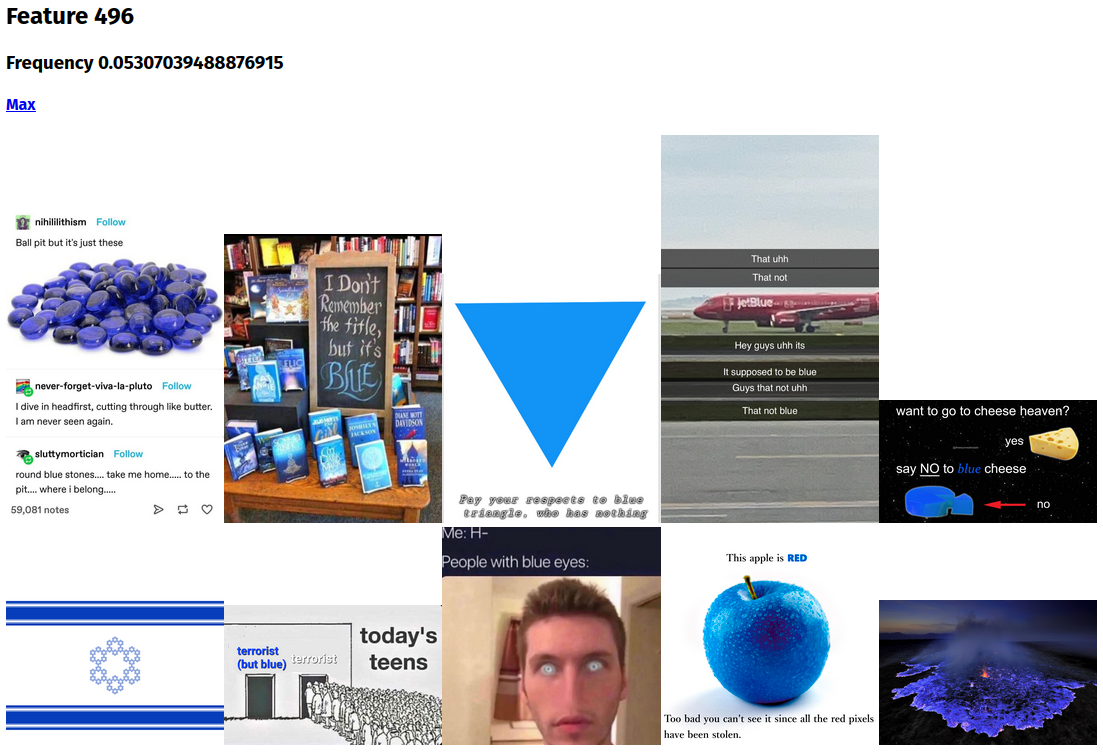
This is close to but slightly different from the results for searching with the text "blue".
This is, at present, just a curiosity, but I expect it to be a valuable part of my future plans for meme search.
Toy Models of Superposition, Elhage et al. I think this was known to some of the field beforehand as "polysemanticity", but I know about it through mechinterp. ↩︎
Taking features out of superposition with sparse autoencoders, Sharkey et al. ↩︎
Sparse Autoencoders Find Highly Interpretable Features in Language Models, Cunningham et al. ↩︎
Interpreting and Steering Features in Images, Daujotas, G. ↩︎
Scaling and evaluating sparse autoencoders, Gao et al. ↩︎
It would be cleaner to simply have more data, but that isn't practical right now. ↩︎