MemeThresher: efficient semiautomated meme acquisition with AI
Updated 2024-04-22 / Created 2024-04-22 / 1.54k words
Absurd technical solutions for problems which did not particularly need solving are one of life's greatest joys.I think what you need to do is spend a day in the data labeling mines.
One common complaint about modern AI is that it takes away valuable aspects of the human experience and replaces them with impersonal engineering. I like impersonal engineering, and since 2021 (prior, in fact, to Meme Search Engine) have been working on automatically determining whether memes were good, with a view to filtering the stream of memes from Reddit for good ones automatically. Unfortunately, at the time I lacked the knowledge, computing power and good enough pretrained models to pull it off. Now I have at least some of those things, and it works. Somewhat.
Reddit is still the primary source for memes, or at least the kind of somewhat technical memes I like. Despite the API changes last year, Reddit still has an excellently usable API compared to its competitors[1] for my purposes – some very simple code is able to crawl a multireddit and download metadata and images from a custom set of subreddits. I gathered 12000 images from subreddits I had known contained some decent memes.
Modelling
The core of MemeThresher is the meme rating model, which determines how good a meme is. Some of the people I talked to said this was "subjective", which is true, but this isn't really an issue – whether a meme aligns with my preferences is an objectively answerable question, if quite a hard one due to the complexity of those preferences and the difficulty of conveying them compactly. I consulted #off-topic[2] members on how to do this, and got the suggestion of using a Bradley-Terry model. A Bradley-Terry model fits scalar scores to pairwise comparisons (of win probability, but I just set them to 0.95 or 0.05 depending on which one was preferred) – you've probably interacted with this in the form of the "elo" system in chess. I used SigLIP embeddings as the input to the model, as it's already deployed for Meme Search Engine and is scarily capable. I ensemble several models trained on the same data (in a different order and with different initialization) together so that I can compute variance on the same pairs to find what the model is most uncertain about[3].
The data labelling mines
Even with a powerful pretrained model providing prior knowledge about the world and about memes, making this work at all needs a decent quantity of training data. I wrote a custom script to allow rapidly comparing pairs of memes. This uses the existing Meme Search Engine infrastructure to rapidly load and embed images and has a simple keyboard interface for fast rating. It was slightly annoying, but I got about a thousand labelled meme pairs to start training. Perhaps less data would have worked, but it did not take that long (I think an hour or two) and there were enough issues as things stood.
Staring at loss curves for several hours
It has been said that neural nets really want to learn – even if you make mistakes in the architecture or training code, a lot of the time they will train anyway, if worse than they should. However, they don't necessarily learn what you want. With just a thousand data points to train on, and a nontrivial model (an ensemble of MLPs), it would immediately overfit after a single epoch. I tried various regularization schemes – increasing weight decay a lot, dropout, and even cutting the model down as far as linear regression – but this either resulted in the model underfitting or it overfitting with a slightly stranger loss curve.
Fortunately, I had sort of planned for this. The existing pairs of memes I rated were randomly selected from the dataset and as a result often quite low-signal, telling the model things it "already knew" from other examples. None of this is particularly novel[4] and active learning – inferring what data would be most useful to a model so you can gather and train on it – is widely studied. I used the least bad checkpoint to find the highest-variance pairs out of a large random set, then manually rated those – they were given a separate label so I could place those at the end of training (this ultimately seemed to make the model worse) and have a separate validation set (helpful). I also looked into finding the highest-gradient pairs, but it turns out this isn't what I want: they are in some sense the most "surprising", and the most surprising things were apparently things which were already clear to the model being overturned by a new data point, not marginal cases it could nevertheless learn from.
The new data seemingly made it slightly less prone to overfitting, but, "excitingly", it would achieve the lowest validation loss for the early set and new set at different steps. I was not able to resolve this, so I just eyeballed the curve to find a checkpoint which a reasonable balance between these, ran another round of active learning and manual labelling, and trained on that. It was very hard for the model to learn that at all, which makes sense – many of the pairs were very marginal (I didn't include a tie option and didn't want to add one at a late stage, but it would perhaps have been appropriate). At some point I decided that I did not want to try and wrangle the model into working any longer and picked a good-enough checkpoint to use.
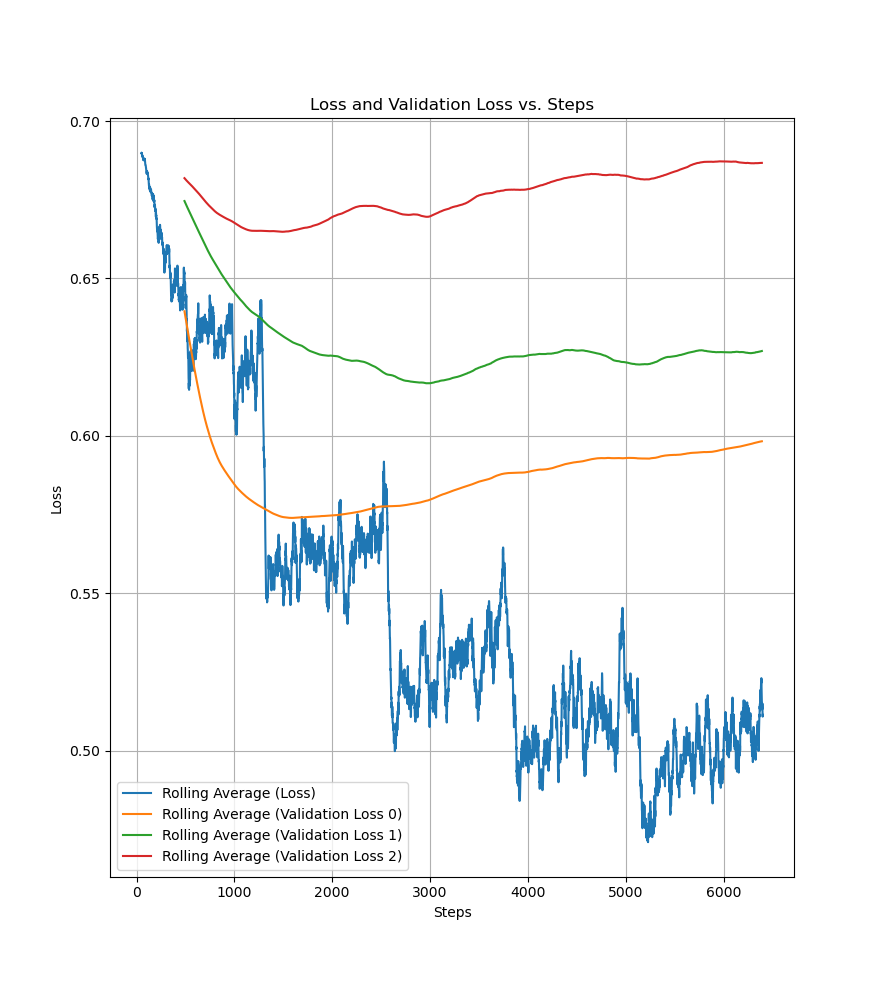
Ultimately, I picked step 3000 from this run.
I ran a final evaluation on it: I rated my whole meme dataset, got 25 memes at various percentiles of score, and manually determined how many were good enough for meme library inclusion. This result is actually not particularly desirable: ideally all the suitable memes should be right of some line and the ones on the left of that all bad. On the advice of my friend, I also plotted a ROC curve, as well as another one I don't know a standard name for (the cumulative probability of a meme being good by score), using a new dataset where I manually considered 150 random memes individually.
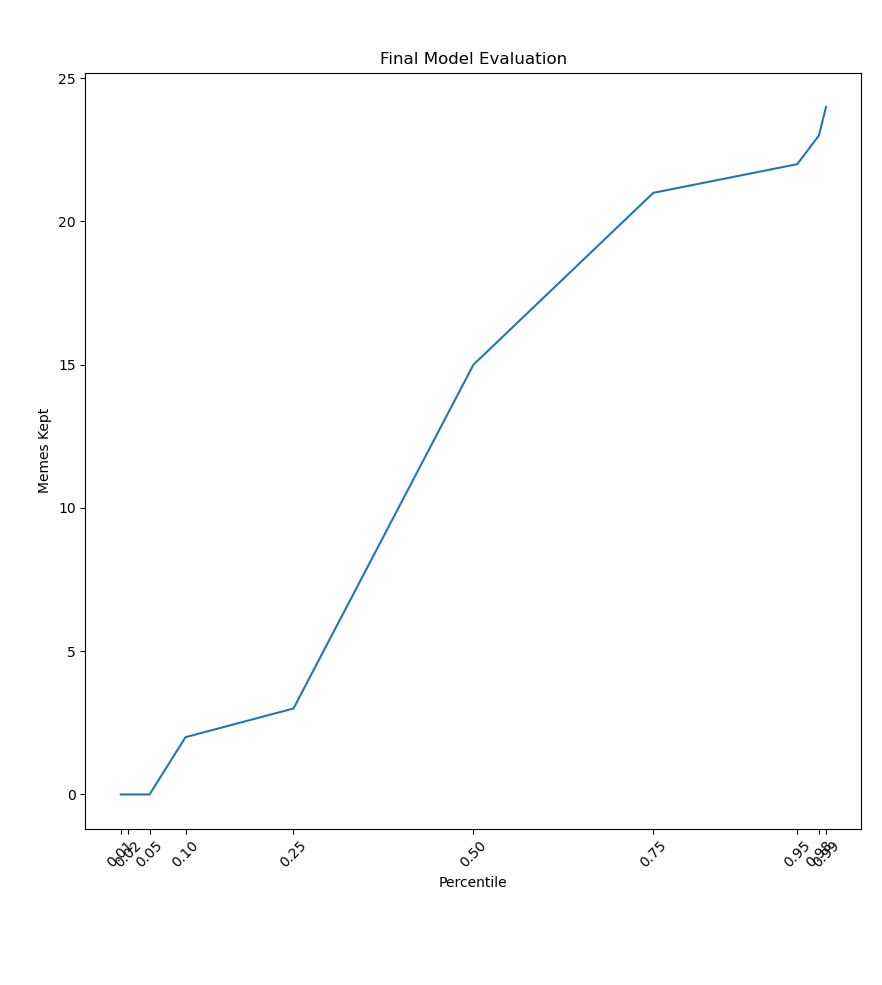
It is sort of annoying to see the culmination of three days of work as a boring matplotlib graph rather than something cooler.
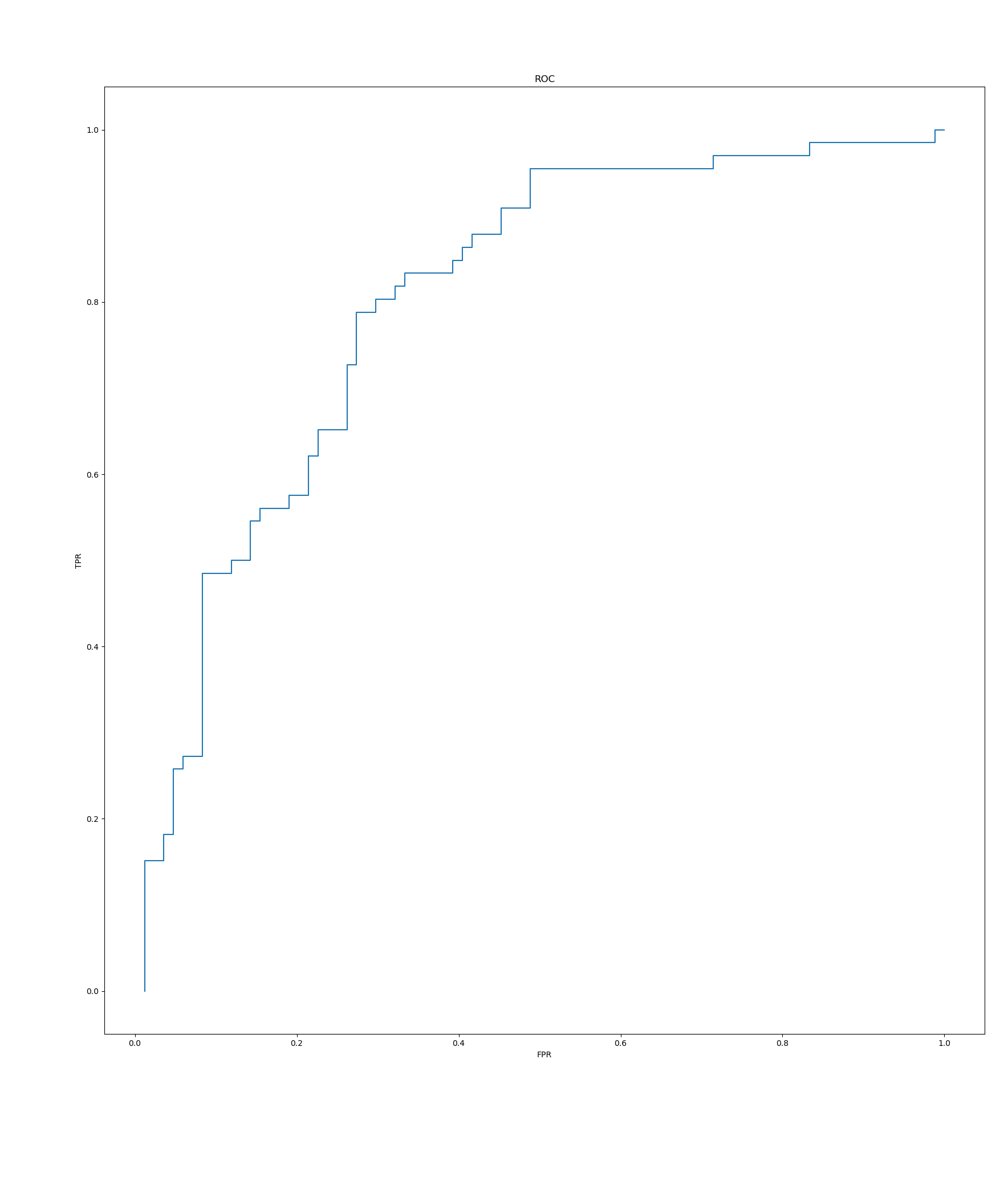
AUROC 0.801.
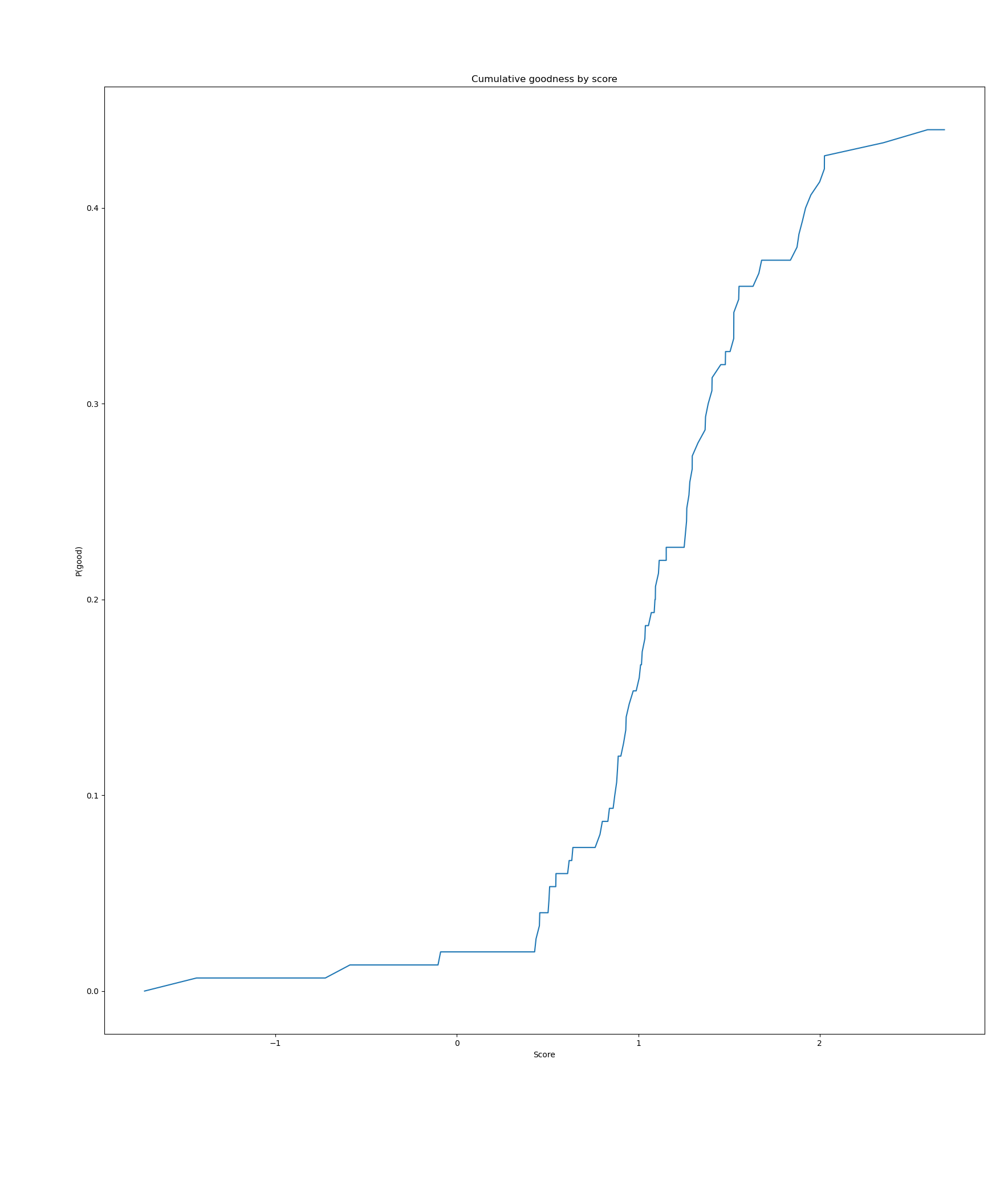
I actually plotted this by accident while misunderstanding how ROC worked very badly.
Deployment
The ultimate purpose of the software and model is of course to find good memes with less effort on my part, not to produce dubiously good ROC curves. Handily, this was mostly doable with my existing code – Meme Search Engine to embed images in bulk, a slight modification of the dataset crawler to get new images, a new frontend to allow me to select and label memes for library inclusion, and a short script to orchestrate it and run the scoring model.
Improving the model
Since this is a blog post and not an actual research paper, I can say that I have no idea which parts of this were necessary or suboptimal and declare the model good enough without spending time running ablations, nor do I have to release my folder of poorly organized run logs and models[5]. However, I do have a few ideas for interested readers which might improve its capabilities:
- Use a bigger model than mine and regularize it better.
- Do proper hyperparameter sweeps rather than a brief grid search I did midway through to look at learning rates and weight decay values.
- Use a better pretrained image encoder (I don't know if there are any, at least for this usecase) or use the pre-pooling output rather than just embeddings.
- Shorter-iteration-cycle active learning: I did this very coarsely, doing only two rounds with 256 images at once, but I think it should be practical to retrain the model and get a new set of high-signal pairs much more frequently, since the model is very small (~50M parameters). This might allow faster learning with fewer samples.
- Rather than training a model directly to predict scores and then winrates, train a single model to predict winrate between pairs given both embeddings, then either use that directly or use it to generate synthetic data for a scalar-score model.
Thanks to AI_WAIFU, RossM, Claude-3 Opus and LLaMA-3-70B for their help with dataset gathering methodology, architectural suggestions, plotting code/naming things and the web frontends respectively!
This is more because theirs are awful than because its is especially good. ↩︎
You know which one. ↩︎
In retrospect, it would probably also have been fine to take pairs where the predicted winrate was about 0.5. ↩︎
Someone has, in fact, built a similar tool which they used to find the best possible catgirl, but I think they do logistic regression (insufficiently powerful for my requirements) and understanding and rearranging their code to my requirements would have been slower than writing it myself. ↩︎
Actually, most research wouldn't do this because research norms are terrible. ↩︎