Minoteaur
Updated 2023-08-28 / Created 2023-06-06 / 2.49k words
The history of the feared note-taking application.The goal is to have smart walkable high-density mixed-use note systems.
If you've talked to me, you've probably heard of Minoteaur. It was conceptualized in 2019, when I determined that it was a good idea to take notes on things in a structured way, looked at all existing software, and was (as usual, since all software is terrible; I will probably write about this at some point) vaguely unsatisifed by it. I don't remember the exact details, since I don't have notes on this which I can find, but this was around the time when Roam Research leaked into the tech noösphere, and I was interested in and generally agreed with the ideas of graph-structured note-taking applications, with easy and fast flat organization. However, Roam itself was (is) closed-source SaaS and thus obviously unsuitable for personal notes, and made weird technical decisions I didn't like, as did the best available alternative (TiddlyWiki with various plugins I read about). Most software also didn't seem to care about data durability or revision history, which is important to me, since notes are less useful if you can't rely on their future availability. Thus, Minoteaur: I would just write something myself to my very specific requirements and preferences, with all the features I needed and none I didn't. This did not go as planned.
The rewrite treadmill
While the exact history of Minoteaur is lost to overly sparse notes on it, the lack of publicly released development versions, and my lack of documentation, the rough outline is fairly clear. An early mostly-server-rendered Node.js/PostgreSQL version (Minoteaur 1) was written in early 2019, with very basic features: you could edit pages, categorize them, link to them, view revisions and even highlight syntax for no particularly good reason. Being designed as a single-user system, it was deliberately designed with basically no security, and I had some fun on the public instance I had up sometimes as a demo with self-replicating viral pages. As usually happens with sufficiently large projects which I can't neatly complete in pieces, I got bored of working on this, especially since useful changes would have required a big rewrite. It did, at least, get away with supporting its capabilities using impressively little code. While wrong people believe that better software involves more code, I, as an enlightened programmer, recognize that you should write as little code as possible, as more code means more bugs and more work to write and maintain it.

Self-replicating Minoteaur pages on the legacy public Minoteaur. I can no longer get it to run, so I don't have any other images.
After deciding that I really did need something which worked even if it wasn't perfect, I settled on... installing DokuWiki – while a PHP application and not particularly modern featurewise, it was known to be robust, supported most of what I wanted, and basically worked. I even dabbled in the horrors of PHP to make some tweaks and plugins I wanted work.[1]
However, the dream of Minoteaur had not yet died. Prototypes were developed and reengineered for new, exciting Minoteaurs based on Node.js, SQLite3 and single-page application technologies, to implement a more TiddlyWiki-like UI with multiple pages open at once and offer generally better interactivity. Unfortunately, despite the nicer interface and useful Markdown preview mode, these proved frustrating to work on, due to the usual difficulties of maintaining consistency between client code with persistent state and a server which also has persistent state, and I ultimately consigned Minoteaur 2 and 3 to the depths of my project folder in mid-2020. It was also somewhat slow, due to the overhead of parsing Markdown into a parse tree and then rendering that parse tree to virtual DOM and then rendering virtual DOM to actual DOM nodes.
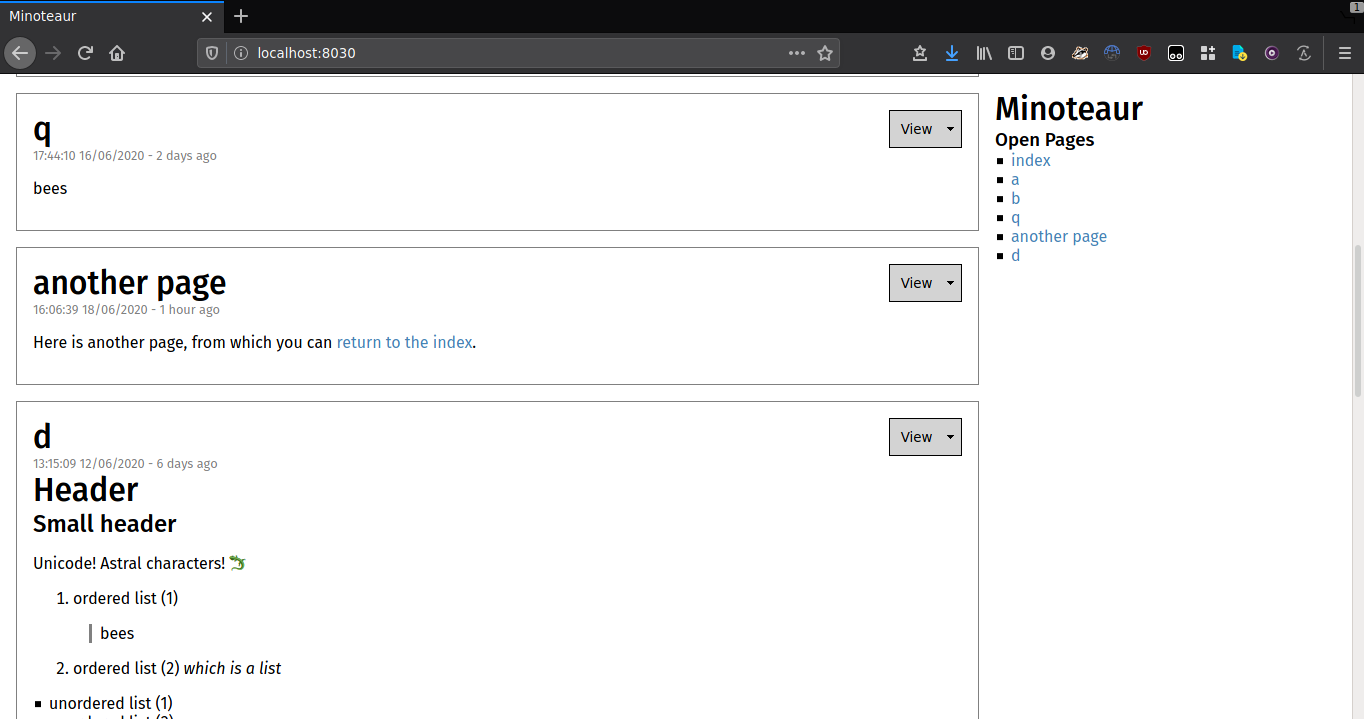
Minoteaur 2's multitasking UI was ultimately abandoned in favour of just using native browser tabs or windows.
While researching for this I thought that Minoteaur 4 didn't exist because of accidents with the numbering scheme, but it turns out that it does, but it's really Minoteaur 1.5.
I had vague memories of a prototype Rust backend for use with a single-page application (with a vaguely RESTful API rather than the usual tightly-coupled RPC designs I use) which I had assumed was developed after the Node.js ones, but it was made significantly before those in late 2019.
I presumably mostly forgot about it because it wasn't very good or useful.
This was still the early days of Rust's use in web things, so it used synchronous IO, a version of warp so early that some of the filters had silly names like post2 or get2 to maintain some semblance of backwards compatibility, and Diesel.
I also apparently never wrote a client to go with it, so I'm not really sure how it was meant to work.
Minoteaur 5 does assuredly exist, and it was developed later in 2020.
Rust having advanced somewhat since the days of Minoteaur 4, it uses asynchronous IO libraries, and switches back to server-rendering with maud HTML templates.
It "mostly worked" at the level of Minoteaur 1, but also proved annoying to work on, especially since the Markdown parsing mechanisms are quite annoying (none of the Markdown parsing libraries are particularly easy to extend, but pulldown-cmark returns an event stream, so I had to write some somewhat terrible code to streamingly process that and count up [s and ]s, which then got rewritten to only partly do the weird streaming parsing and to mostly hand it off to regexes).
When I got sufficiently annoyed by that again, I rewrote it in Nim for Minoteaur 6. Nim is sort of how I would design a programming language, both in the sense that it makes a lot of nice decisions I agree with (extensive metaprogramming, style insensitivity) and in that it's somewhat quirky and I don't understand why some things happen (particularly with memory management, for which it has seemingly several different incompatible systems which can be switched between at compile time[2]). It has enough working libraries for things like SQLite and webservers that I thought it worth trying anyway, and it was indeed the most functional Minoteaur at the time, incorporating good SQLite-based search, backlinks, a mostly functional UI, partly style-insensitive links, a reasonably robust parser, a decent UI, and even DokuWiki-like drafts in the editor (a feature I end up using quite often due to things like accidentally closing or refreshing pages). However, I got annoyed again by the server-rendered design, the terrible, terrible code I had to write to directly bind to a C-based GFM library (I think I at least managed to make it not segfault, even though I don't know why), and probably some things I forgot, leading to the next version.
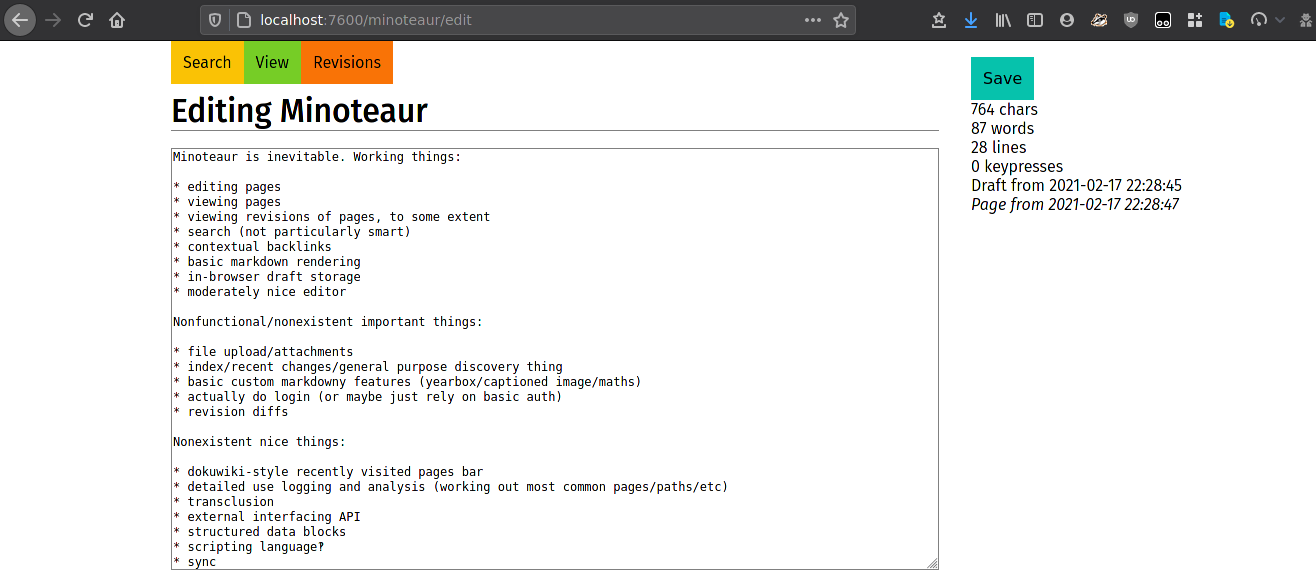
The Minoteaur 6 "two-pane" editor UI.

Its search mechanism worked, but with some UI problems.

Minoteaur 6 had an extensive login fallback system.
Python is my go-to language for rapid prototyping, i.e. writing poor-quality code very quickly, so it made some sense for me to rewrite in that next in 2021. Minoteaur 7 was a short-lived variant using server rendering, which was rapidly replaced by Minoteaur 7.1, which used a frontend web framework called Svelte for its UI[3]. It contained many significant departures from all previous Minoteaurs, mostly for the better: notably, it finally incorporated indirection for pages. While all previous implementations had just stored pages under their (somewhat normalized) title, I decided that not structuring it that way would be advantageous in order to allow pages to be renamed and referred to by multiple names, so instead pages have a unique, fixed ID and several switchable names. This introduced the minor quirk that all Markdown parsing and rendering was done on the backend, which was not really how I'd usually do things but did make a good deal of the code simpler (since it is necessary to parse things there to generate plaintext for search). As a search mechanism, I also (since Python made this practical) used deep-learning-based semantic search (using Sentence Transformers) rather than the term-based mechanisms in SQLite. This was quite easy to do thanks to the hard work of library developers, although I did write my own in-memory vector index for no clear reason, and frequently worked quite well (surfacing relevant content even if it didn't contain the right keywords) but with some unreliability (keyword matches were not always found). It also got the furthest yet in terms of general usability, mostly because I implemented file upload, which I think is necessary for any useful notes software (you do, at the very least, want to be able to add and reference images). Ultimately, for some reason I forgot (I think mostly database management this time), I decided that I disliked the code and rewrote it yet again, leading to Minoteaur 8.
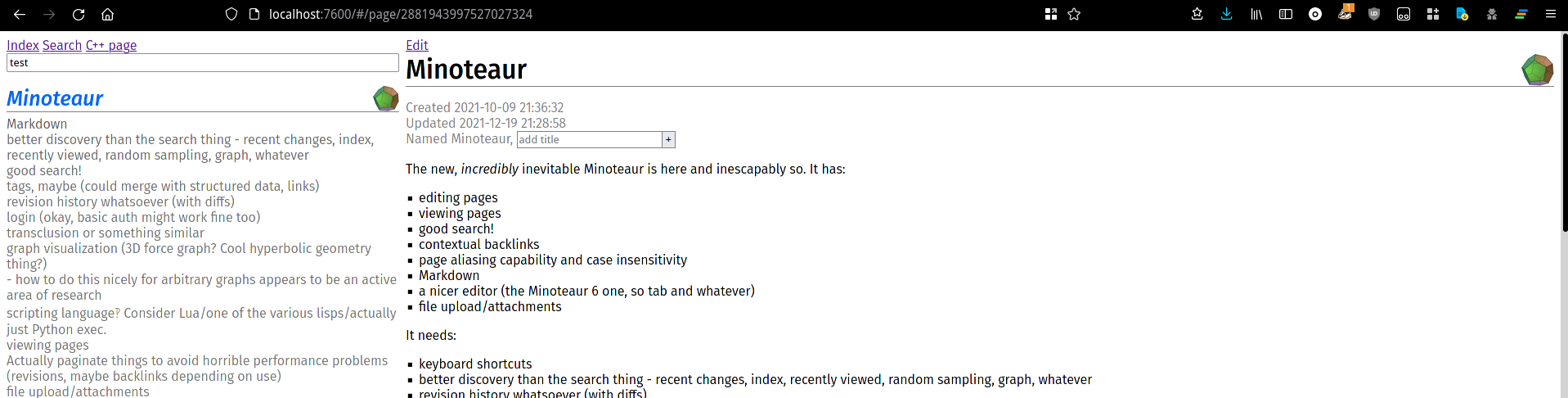
Minoteaur 7.1 introduced a new UI style and more effectively used the width of standard horizontal screens with the search sidebar. It also incorporated page icons for the first time.

An earlier prototype displaying its search capabilities.
Minoteaur 8 was a rewrite in Rust again, starting in February 2022, using much of the frontend code from Minoteaur 7.1 but with a completely different backend but with a similar architecture, apart from the fact that instead of using SQLite directly and "sensibly", it uses it to store persistent versions of objects (revisions, pageviews or pages) for which live copies and indices are held in memory. Since notes aren't really that big, I worked out that even under pessimistic assumptions the RAM requirements would be lower than those of the JS/Python interpreter processes running previous Minoteaurs, which were not particularly large anyway (more on this in my future writing on how all software is terrible), and this made a lot of the code simpler due to not having to limit data structures to what SQLite supports and not having to deal with async IO for read operations.
Despite considerable success in making it work to the same extent as previous Minoteaurs (files, search, backlinks, Markdown, etc) and even somewhat further (nicer Markdown syntax, and a three-pane UI), development was mysteriously halted for a while in March and nonmysteriously (some inconsistencies in how context for backlinks versus for search worked which felt annoying to fix) in July after I picked it back up. This April, I happened to look again for some reason, and found that the problem was in fact easy if reframed slightly, then did everything else I wanted for usability parity with my DokuWiki install over the course of three days, wrote an import and DokuWiki migration script, redid some of the syntax for more reliable parsing, and finally transitioned away from DokuWiki after slightly less than 4 years.

Minoteaur's Minoteaur page.

To allow discovery of interesting content you may have forgotten, Minoteaur incorporates a random pages list.
So what does it do?
It's described somewhere as a "wiki-styled graph-structured personal note-taking application", and this is basically correct, as I would hope, because I wrote that. It's the intersection of what I wanted and what I could be bothered to build in the domain of notes. Despite significant inspiration from things like Roam and TiddlyWiki, I don't implement their particularly unique and special features (the strong focus on the graph and the block structure of Roam, and the metaprogrammability/LISPness of TiddlyWiki), because they seem excessive and I don't particularly care – in the spirit of the Pareto principle, most of the value to me comes from relatively basic features. It can, however:
- view, store and search pages.
- search through them using BM25 ranking and moderately fuzzy keyword search (as well as in titles with a different mechanism).
- automatically display backlinks, with a paragraph or so of autoextracted context.
- link to pages case-insensitively and with multiple different aliases.
- render GitHub-flavored Markdown with the addition of wikilinks and KaTeX maths blocks.
- be controlled mostly with keyboard shortcuts.
- show old versions of pages.
- categorize pages by (hierarchical) tags.
- store files, and use them as icons for pages for easy recognition (mostly in search results).
- work on phones, somewhat (it was pretty difficult to reliably detect phones as opposed to vertical monitors, and when I got it to work it broke again after my monitor layout changed and Firefox handled it weirdly).
- run JS on the serverside as part of Markdown processing, in lieu of a plugin API (I had to ship the interpreter anyway for KaTeX).
- associate structured data (text or numbers) with pages, and run queries based on that.
Should you use it? Probably not: while it works reliably enough for me, this is because I am accustomed to its strangeness and deliberately designed it to my requirements rather than anyone else's, sometimes in ways which are very hard to change now (for example, adding things like pen drawings would be really hard structurally, and while there was a Minoteaur 8 prototype with a different architecture which would have made that easier, it was worse to write most code for so I didn't go ahead with that), and can rewrite and debug it easily enough if I have to. Other people cannot. I am not writing this in order to convince people to switch over (that would create support requests) but to provide context and show off my technical achievement, such as it is.
Future directions
While it works as-is, mostly, active real-world use has given me ideas about how it could be better.
At this time, I'm mostly interested in improving the search mechanism to include phrase queries, negative queries and exact match queries, better integration with external tools (for example, with some engineering effort I could move Anki card specifications into notes and not have to maintain that separately), and a structured data mechanism for attaching machine-readable content to pages.
I ultimately did add some of these. The search mechanism does now allow "exact" and "negative" queries, although it still has some brokenness I intend to fix at some point, and there's a fully featured structured data mechanism. Pages can have a list of key/value pairs attached (numeric or textual) and can then be queried by those using a few operators in the search.
I think this was just nice syntax for superscript/subscript formatting which I ultimately realized could just be replaced by TeX, and some ugly hacks to stop it complaining when I upgraded to PHP 8. ↩︎
Apparently it standardized on reference counting with cycle detection now. ↩︎
I use this for most new projects now. It's very pleasant to use, and apparently quite fast, which I value to some extent. ↩︎