Lessons learned from Maghammer
Updated 2025-02-13 / Created 2024-07-06 / 1.62k words
I got annoyed and rewrote everything.If Google Search does not return the result the user wanted because the user typed the wrong thing in the search box, that is a failure on Google's part, not a failure on the user's part. Conversely, if Google Search does return the result the user wanted because the user typed the correct thing in the search box, that is a failure on Google's part, not a failure on the user's part.
Maghammer, the search and data management system I previously outlined, has been reasonably successful, as it's frequently been able to find things which were hard to look up any other way. But, like all software, it has problems. It has somewhat more than usual, being an assemblage of very ugly Python scripts made out of expediency and laziness. Many of these were knowable in advance if I had paid more attention, but I have at least gained some actionable information from its slightly-less-than-a-year of production use. Due to vague dissatisfaction with Python and mounting implementation problems, I've done a full rewrite in Rust. As the code has now gone from "active affront to God" to merely "quite inelegant", I will be releasing it shortly (though I do not expect it to be very usable for other people). Here's what I've determined and changed:
Postgres and PGVector are very good
Give someone state and they'll have a bug one day, but teach them how to represent state in two separate locations that have to be kept in sync and they'll have bugs for a lifetime.
RDBMSes like PostgreSQL and SQLite are pieces of software I very much appreciate. Their data model may not nicely fit everything I do, but in an industry where many chase after convoluted solutions to problems they do not actually have they are a bright point – they Just Work, centralizing data such that I can access it across languages and manually using pleasant tools, and have excellent consistency guarantees. When it's possible to use them as the only location my code persists state, I will generally do that for the sheer simplicity and reliability gains.
Unfortunately, the old version of Maghammer was not built like this. Its search index was built on SQLite FTS5, which for some bizarre reason requires manually[1] synchronizing main table content with FTS table content on pain of integrity failures, using an oddly procedural API, and with a separate FAISS index for the semantic search component which also had to be periodically kept in sync. This led to a lot of annoying code and some minor but annoying bugs.
Postgres has no competent lexical (word-based) full text search built in[2], and I haven't yet found an extension providing this in a satisfying way, but it does have PGVector, which can store and index vectors. I had previously evaluated it for Maghammer, but determined that it was unsuitable – ANN indices were problematically slow to build, and without half-precision vector support it used lots of storage and RAM unnecessarily.
However, with PGVector getting new features (half-precision vector support and faster but more storage-hungry HNSW indices), me realizing that I had not properly performance-tuned Postgres[3], and some fixes to the embedding generation process itself, it became practical to use it as the main vector store, so my rewritten version stores all its data in Postgres (rather than a variety of SQLite databases and a FAISS index) along with the embeddings.
Smarter tokenization and embeddings
One significant problem with the last version is that the context window used for embeddings was short, so queries which would only match given a large window of the text returned irrelevant results. This is because tokenization is terrible[4] and I avoided having to deal with it in the indexing code by chunking text by sentence until a character length limit was exceeded. In all reasonable circumstances (I lose no sleep over discarding weird Unicode) this kept it under the length limit, but usually very far under the length limit. The new code is tokenization-aware and breaks inputs into chunks by tokens, which results in oddly placed breaks between chunks but makes them much longer.
This has the additional advantage of producing fewer sentence embedding vectors, which makes the index more efficient.
As a minor consequence of picking from models released about a year later, I also replaced the e5-large-v2 model previously used for embeddings with the same-sized-and-apparently-better snowflake-arctic-embed-l, since it claims better retrieval performance and is more trustworthy, to me, than the Chinese models also claiming that.
This has now been replaced again with ModernBERT-Embed-Large for the greater context length, maybe better runtime and better retrieval performance. The long context leads to some VRAM issues with large batches, which I have not yet been able to resolve cleanly.
The model uses a prefix to indicate whether an input is a query or a passage to match against, so I've also split columns into "short" and "long" to determine whether this prefixing mechanism is used for queries or not - without this, short passages are privileged, especially ones containing, for some ridiculous reason[5], the literal text ModernBERT-Embed-Large handles this better, so this mechanism is now legacy unless I also add a non-semantic index.passage. This has its own problems, so I might need an alternative solution.
The quantitative data is not all that helpful
While I could in principle get useful results out of analyzing things like web browsing activity by day and whether my step count is correlated with anything of note, I have not had any compelling reason to do this yet, and this would likely require complex dedicated analysis scripts and frontends to do well. Datasette's ability to run and nicely render custom SQL queries is cool, but not very relevant to this – I've only ever used it about five times in total.
Sharded vector indices
Previously, all embeddings from all columns of all tables indexed by the system were stored in a single FAISS index and then resolved to their original sources after a query was done. I'm not actually sure why I did this – presumably because it made the embedding generation code simpler – but this had a number of problematic consequences.
None of the ANN index algorithms in wide use[6] are able to efficiently handle simultaneously searching by the vector component and normal RDBMS-like columns – if you want to find all good matches with a certain tag, or after a certain date, for instance, you have to do a linear scan through the rows returned from your vector search, which degrades to a linear scan through your entire database as satisfying results become rarer. The upshot, for my application, is that it was not possible to efficiently filter search results by which type of data (media subtitles, personal notes, archived PDFs, etc) they came from.
By instead creating separate tables and thus indices for each table and each column of text, and querying them in parallel, it's possible to cheaply get results from specific text columns, though of course this does not generalize to queries splitting by other fields.
Most of Datasette is unnecessary, at least for me for this
The choice to use Datasette for the UI and scaffolding of the original version was deliberately made to save on development time and build a mostly working prototype quickly. It would have been impractical for me to reimplement all of it on hacky Rust, but I didn't actually have to: the features I actually used most were general text search, LIKE queries on some columns, viewing individual records and very basic table filtering. This was much easier to cover than the entire featureset.
Making a special-purpose tool gives me more flexibility
Datasette has to be able to usefully read off arbitrary SQLite databases regardless of their structure, and SQLite databases don't encode that much semantic information (there's not even a dedicated type for timestamps, and I've seen everything from RFC 3399 strings to nanoseconds since the Unix epoch to the Julian day). In the rewrite, all tables are explicitly populated by import logic in the program and all tables have some metadata attached so the code can know which columns should be shown in a tabular table view and which contain meaningfully searchable text. This will make it easier to add features like the previously-alluded-to timeline mode. Perhaps it will also be practical to add nice graphs later.
I also got to redesign the UI, inasmuch as I wrote all the UI code and markup from scratch. It's based on the "grey borders and rectangles" design language used for most of my internal tools.
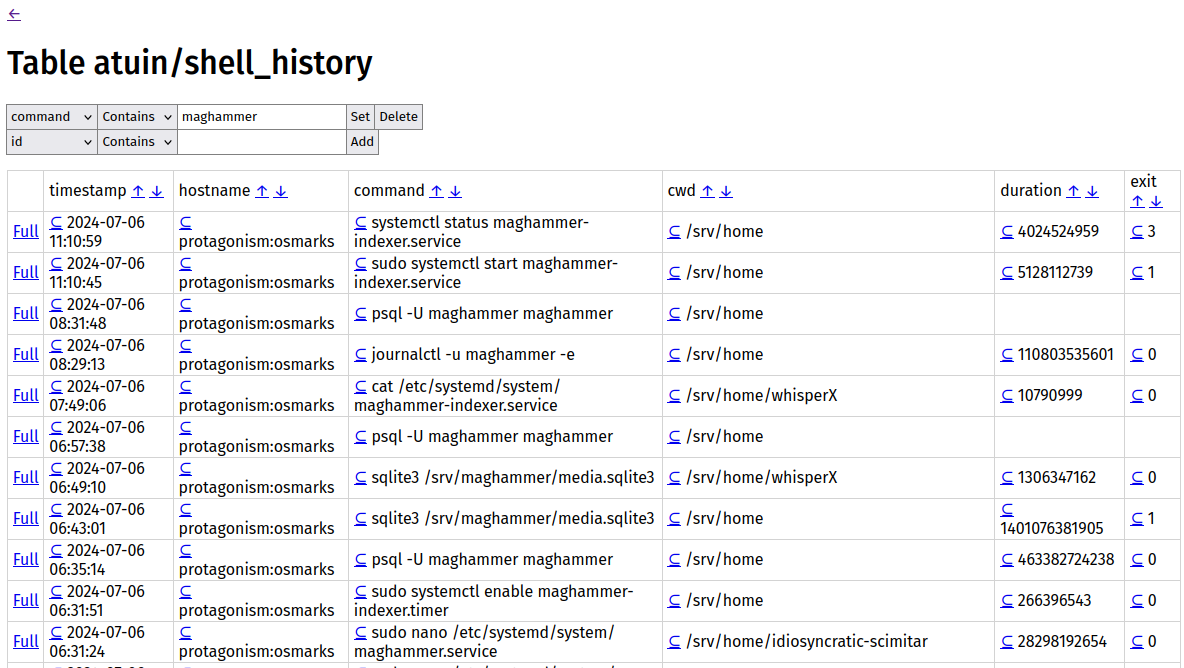
The table view showing some shell history.

An example record view: unlike in Datasette, it is laid out vertically for longer columns.
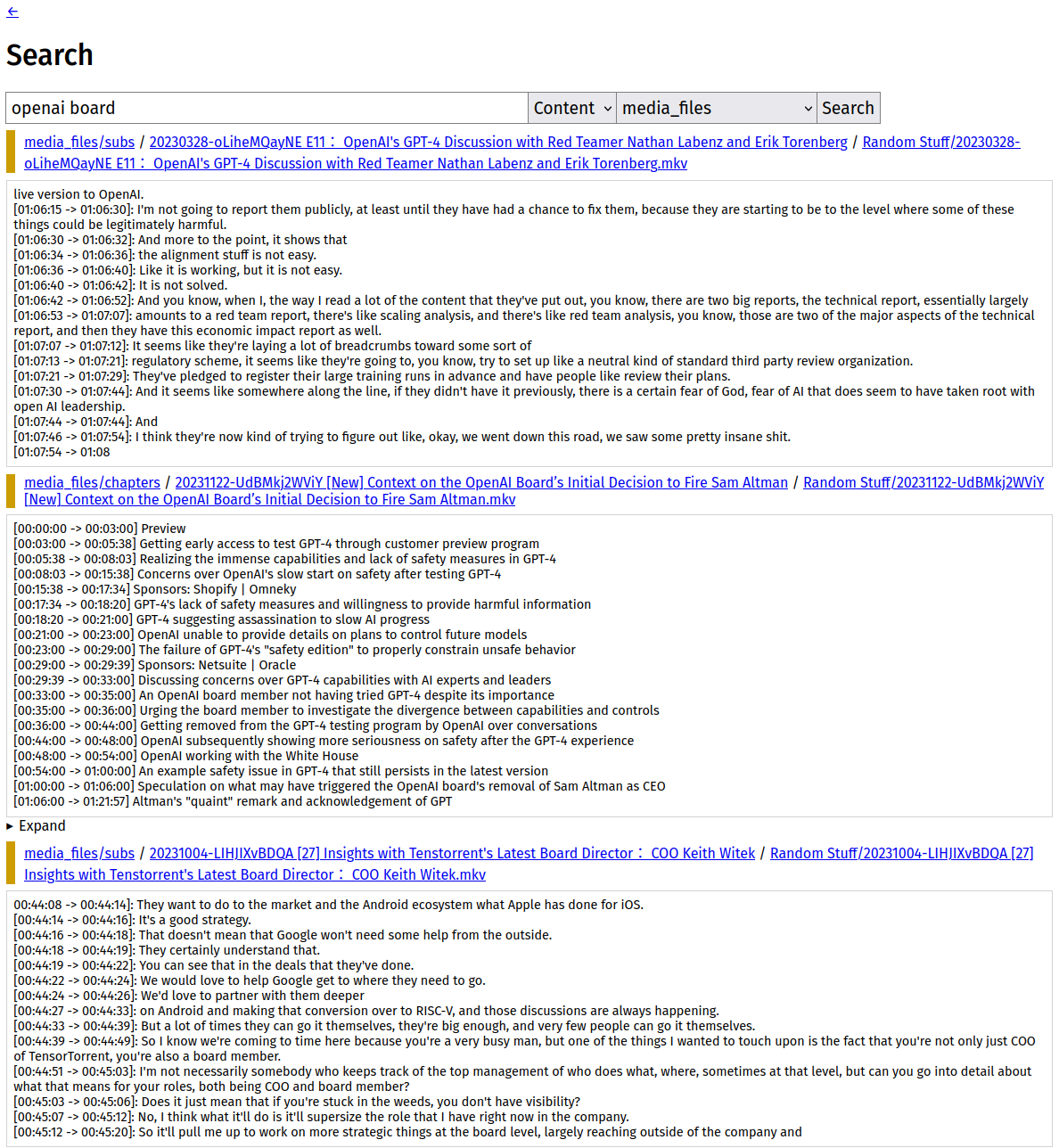
Search results even get colors (by indexer) and will link to the source where available (in this case, the local copy of the video) and the available record.
Or using triggers. I did not do it this way since there had to be non-SQL change tracker code anyway for the semantic search component. ↩︎
The built-in
tsvector/tsquerysystem lacks good ranking and has performance issues. SQLite's is weird to use, but very good at its job. ↩︎By default, it seems to assume you have a computer from the 1990s, and I hadn't fully corrected this. ↩︎
 ↩︎
↩︎I think this is because the overly long instruction for queries contains "passage". ↩︎
There do exist ways to fix this but they're either bad or tricky mathematics. ↩︎