Maghammer: my personal data warehouse
Updated 2024-05-14 / Created 2023-08-28 / 2.59k words
Powerful search tools as externalized cognition, and how mine work.The need to be observed and understood was once satisfied by God. Now we can implement the same functionality with data-mining algorithms.
I have had this setup in various bits and pieces for a while, but some people expressed interest in its capabilities and apparently haven't built similar things and/or weren't aware of technologies in this space, so I thought I would run through what I mean by "personal data warehouse" and "externalized cognition" and why they're important, how my implementation works, and other similar work.
What?
Firstly, "personal data warehouse". There are a lot of names and a lot of implementations, but the general idea is a system that I can use to centrally store and query personally relevant data from various sources. Mine is mostly focused on text search but is configured so that it can (and does, though not as much) work with other things. Proprietary OSes and cloud platforms are now trying to offer this sort of thing, but not very hard. My implementation runs locally on my server, importing data from various sources and building full-text indices.
Here are some other notable ones:
- Stephen Wolfram's personal analytics – he doesn't describe much of the implementation but does have an impressively wide range of data.
- Dogsheep – inspired by Wolfram (the name is a pun), and the basis for a lot of Maghammer.
- Recoll – a powerful file indexer I also used in the past.
- Rewind – a shinier more modern commercial tool (specifically for MacOS...) based on the somewhat weird approach of constantly recording audio and screen content.
- Monocle – built, apparently, to learn a new programming language, but it seems like it works well enough.
You'll note that not all of these projects make any attempt to work on non-text data, which is a reasonable choice, since these concerns are somewhat separable. I personally care about handling my quantitative data too, especially since some of it comes from the same sources, and designed accordingly.
Why?
Why do I want this? Because human memory is very, very bad. My (declarative) memory is much better than average, but falls very far short of recording everything I read and hear, or even just the source of it[1]. According to Landauer, 1986's estimates, the amount of retrievable information accumulated by a person over a lifetime is less than a gigabyte, or <0.05% of my server's disk space[2]. There's also distortion in remembered material which is hard to correct for. Information is simplified in ways that lose detail, reframed or just changed as your other beliefs change, merged with other memories, or edited for social reasons.
Throughout human history, even before writing, the solution to this has been externalization of cognitive processing: other tiers in the memory hierarchy with more capacity and worse performance. While it would obviously be advantageous to be able to remember everything directly, just as it would be great to have arbitrarily large amounts of fast SRAM to feed our CPUs, tradeoffs are forced by reality. Oral tradition and culture were the first implementations, shifting information from one unreliable human mind to several so that there was at least some redundancy. Writing made for greater robustness, but the slowness of writing and copying (and for a long time expense of hardware) was limiting. Printing allowed mass dissemination of media but didn't make recording much easier for the individual. Now, the ridiculous and mostly underexploited power of contemporary computers makes it possible to literally record (and search) everything you ever read at trivial cost, as well as making lookups fast enough to integrate them more tightly into workflows. Roam Research popularized the idea of notes as a "second brain"[3], but it's usually the case that the things you want to know are not ones you thought to explicitly write down and organize.
More concretely, I frequently read papers or blog posts or articles which I later remember and want to retrieve – perhaps they came up in a conversation and I wanted to send someone a link, or a new project needs a technology I recall there being good content on. Without good archiving, I would have to remember exactly where I saw it (implausible) or use a standard, public search engine and hope it will actually pull the document I need. Maghammer (mostly) stores these and allows me to find them in a few seconds (fast enough for interactive online conversations, and not that much slower than Firefox's omnibox history search) as long as I can remember enough keywords. It's also nice to be able to conveniently find old shell commands for strange things I had to do in the past, or look up sections in books (though my current implementation isn't ideal for this).
How?
I've gone through a lot of implementations, but they all are based on the general principle of avoiding excessive effort by reusing existing tools where practical and focusing on the most important functionality over minor details. Initially, I just archived browser history with a custom script and stored SingleFile HTML pages and documents, with the expectation I would set up search other than grep later. I did in fact eventually (November 2021) set up Recoll (indexing) and Recoll WE (to store all pages rather than just selected ones, or I suppose all of the ones without only client-side logic), and they continued to work decently for some time. As usually happens with software, I got dissatisfied with it for various somewhat arbitrary reasons and prototyped rewrites.
These were not really complete enough to go anywhere (some of them reimplemented an entire search engine for no particular reason, one worked okay but would have been irritating to design a UI for, one works for the limited scope of indexing Calibre but doesn't do anything else) so I continued to use Recoll until March 2023, when I found Datasette and the author's work on personal search engines and realized that this was probably the most viable path to a more personalized system. My setup is of course different from theirs, so I wrote some different importer scripts to organize data nicely in SQLite and build full text search indices, and an increasingly complicated custom plugin to do a few minor UI tweaks (rendering timestamp columns, fixing foreign keys on single-row view pages, doing links) and reimplement something like datasette-search-all (which provides a global search bar and nicer search UI).
Currently, I have custom scripts to import this data, which are run nightly as a batch job:
- Anki cards from anki-sync-server's database – just the text content, because the schema is weird enough that I didn't want to try and work out how anything else was stored.
- Unorganized text/HTML/PDF files in my archives folder.
- Books (EPUB) stored in Calibre – overall metadata and chapter full text.
- Media files in my archive folder (all videos I've watched recently) – format, various metadata fields, and full extracted subtitles with full text search.
- I've now added WhisperX autotranscription on all files with bad/nonexistent subtitles. While it struggles with music more than Whisper itself, its use of batched inference and voice activity detection meant that I got ~100x realtime speed on average processing all my files (after a patch to fix the awfully slow alignment algorithm).
- Miniflux RSS feed entries.
- Minoteaur notes, files and structured data. I don't have links indexed since SQLite isn't much of a graph database[4], and my importer reads directly off the Minoteaur database and writing a Markdown parser would have been annoying.
- RCLWE web history (including the
circacheholding indexed pages in my former Recoll install). - Emails dumped from Thunderbird mailboxes (I really did not enjoy writing the parser for that format).
There are also some other datasets handled differently, because the tools I use for those happened to already use SQLite somewhere and had reasonably usable formats. Specifically, Gadgetbridge data from my smartwatch is copied off my phone and accessible in Datasette, Atuin's local shell history database is symlinked in, Firefox history comes from my script on my laptop rather than the nightly serverside batch job, and I also connected my Calibre library database, though I don't actually use that. 13GB of storage is used in total.
This is some of what the UI looks like – it is much like a standard Datasette install with a few extra UI elements and some style tweaks I made:
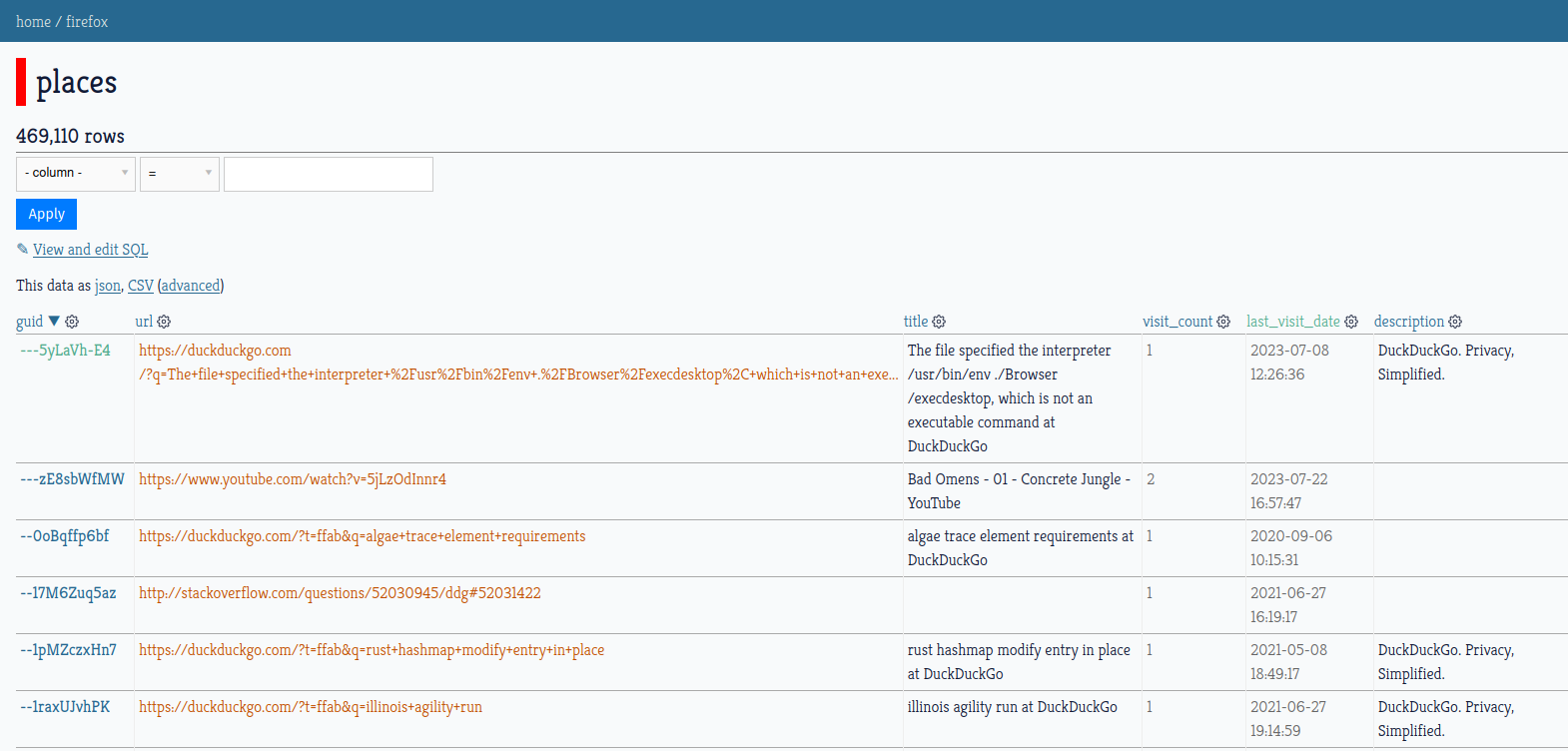
Viewing browser history through the table view. This is not great on narrower screens. I'm intending to reengineer this a little at some point.

The redone search-all interface. My plugin makes clickable links pointing to my media server.

The front page, listing databases and tables and with the search bar.
Being built out of a tool intended for quantitative data processing means that I can, as I mentioned, do some quantitative data processing. While I could in principle do things like count shell/browser history entries by date, this isn't very interesting, and the cooler datasets are logs from my watch (heart rate and step count), although I haven't gotten around to producing nice aggregates from these, and the manually written structured data entries from my journal. For the reasons described earlier I write up a lot of information in journal entries each day, including machine-readable standardized content. I haven't backfilled this for all entries as it requires a lot of work to read through them and write up the tags, but even with only fairly recent entries usable it's still provided significant insight.

A simple aggregate query of my notes' structured data. Redacted for privacy.

Not actually a very helpful format.
While it's not part of the same system, Meme Search Engine is undoubtedly useful to me for rapidly finding images (memetic images) I need or want – so much so that I have a separate internal instance run on my miscellaneous-images-and-screenshots folder. Nobody else seems to even be trying – while there are a lot of demos of CLIP image search engines on GitHub, and I think one with the OpenAI repository, I'm not aware of production implementations with the exception of clip-retrieval and the LAION index deployment, and one iPhone app shipping a distilled CLIP. There's not anything like a user-friendly desktop app, which confuses me somewhat, since there's clearly demand amongst people I talked to. Regardless of the reason, this means that Meme Search Engine is quite possibly the world's most advanced meme search tool (since I bothered to design a nice-to-use query UI and online reindexing), although I feel compelled to mention someone's somewhat horrifying iPhone OCR cluster. Meme Search Engine is not very well-integrated but I usually know which dataset I want to retrieve from anyway.
I've also now implemented semantic search using e5-large-v2 embeddings. It turns out that I have more data than I thought, so this was somewhat challenging. Schematically, a custom script (implemented in a Datasette plugin for convenience, although it probably shouldn't be) dumps the contents of FTS tables, splits them into chunks, generates embeddings, and inserts the embeddings and location information into a new database, as well as embeddings and an ID into a FAISS index. When a search is done, the index is checked, the closest vectors found, filtering done (if asked for) and the relevant text (and other metadata e.g. associated URL and timestamp) found and displayed.
It is actually somewhat more complex than that for various reasons. I had to modify all the importer scripts to log which rows they changed in a separate database, as scanning all databases for new changes would probably be challenging and slow, and the dump script reads off that. Also, an unquantized (FP16) index would be impractically large given my available RAM (5 million vectors × 1024 dimensions × 2 bytes ≈ 10GB), as well as slow (without using HNSW/IVF). To satisfy all the constraints I was under, I settled on a fast-scan PQ (product quantization) index[5] (which fit into about 1GB of RAM and did search in 50ms) with a reranking stage where the top 1000 items are retrieved from disk and reranked using the original FP16 vectors (and the relevant text chunks retrieved simultaneously). I have no actual benchmarks of the recall/precision of this but it seems fine. This is probably not a standard setup because of throughput problems – however, I only really need low latency (the target was <200ms end-to-end and this is just about met) and this works fine.
Future directions
The system is obviously not perfect. As well as some minor gaps (browser history isn't actually put in a full-text table, for instance, due to technical limitations), many data sources (often ones with a lot of important content!) aren't covered, such as conversation history on e.g. Discord. I also want to make better use of ML – for instance, integrating things like Meme Search Engine better, local Whisper autotranscription of videos rather than having no subtitles or relying on awful YouTube ones, semantic search to augment the default SQLite FTS (which uses term-based ranking – specifically, BM25), and OCR of screenshots. I still haven't found local/open-source OCR which is both good, generalizable and usable[6]. Some of the trendier, newer projects in this space use LLMs to do retrieval-augmented generation, but I don't think this is a promising direction right now – available models are either too dumb or too slow/intensive, even on GPU compute, and in any case prone to hallucination. After some time in use use, it seems like the most critical thing to change is how chunks for embedding are generated and organized: a chunk from midway through a document retains no context about the title or other metadata, the ranker doesn't aggregate multiple chunks from within the document properly, and in my laziness (not wanting to bring in a tokenizer) they're way shorter than they have to be.
Another possible redesign feature is a timeline mode. Since my integration plugin (mostly) knows what columns are timestamps, I could plausibly have a page display all relevant logs from a day and present them neatly.
If you have related good ideas or correct opinions, you may tell me them below. The code for this is somewhat messy and environment-specific, but I may clean it up somewhat and release it if there's interest in its specifics.
I suspect this is because of poor precision (in the information retrieval sense) making better recall problematic, rather than actual hard limits somewhere – there are documented people with photographic memory, who report remembering somewhat unhelpful information all the time – but without a way to change that it doesn't matter much. ↩︎
This is the size assuming optimal compression, but obviously the actual brain has many other concerns and isn't storing things that way. The actual hardware probably holds, very roughly, 1015 bits. ↩︎
Zettelkasten and such predate this, but Roam definitely popularized it amongst tech people. ↩︎
The SQLite documentation describes use of recursive common table expressions to implement graph queries, but this, while cool, is not exactly pleasant and elegant. ↩︎
FAISS has some helpful manuals like this describing the various forms available, although there are rather a lot of them which say slightly different things. ↩︎
Phone OSes can do this very well now, but the internals are not open. ↩︎